Hi! At my organization, we are trying to understand trends or differences in experiences of communities who have used our support over the years (we provide counseling for people in crisis). People reaching out to us have the option to fill out an optional, anonymous, voluntary survey where they can choose to self-identify their age, gender, and racial identities. As we begin to look into this information, I was wondering how others working with polytomous race/gender identity survey variables have picked a reference category against which to make comparisons. We don’t want to default to picking the dominant categories (which tend towards white, cis, and male) but we’re trying to understand if there are other logics or ideas for picking a reference group in a way that doesn’t assume that certain communities are the default or “normal” against which to make comparisons. There is also no specific community focus for this research either, so no rationale for treating any one as the reference, which is making the process of selecting a reference group harder ![]() any advice or experiences will be much appreciated! thank you!
any advice or experiences will be much appreciated! thank you!
Thanks for asking this question, as I also struggle with this. I think you’re talking about using the variable in linear statistical models, so I’ll proceed as if that’s the case.
- I have sometimes used what is sometimes called deviation effect coding, in which there is still a reference category, but it’s not special in that its coefficient is just the negative sum of all the other coefficients; the meaning of the coefficients changes slightly, but I like the difference from the grand mean better than the difference from a reference group.
- Or, if I do use referenced dummy coding internally, I might then post-process the results to present some sort of mean effect for each group, not the difference from the reference group.
- If there is only one such categorical variable in a model, I have simply omitted the intercept from the model and included one dummy variable for each category.
- I have also overparameterized the model with an overall mean and added effect from each group but build in constraints that make the problem soluble (e.g. as is common in hierarchical/mixed models).
Are these answers along the lines of what you hoped to receive?
Hey @devyani this is such a great question! I love that you folks are interested in the tricky problem of exploring and explaining gaps or differences between groups without accidentally implying that larger/better-performing/typical-default groups are inherently “better” or “normal” or “the goal”.
I think that @bvancil has brought up some excellent approaches to calculating different kinds of differences and, as they noted, answering slightly different questions. I want to talk more about those too (especially the part about omitting the intercept!).
I’ve got a few basic alternatives to using one category as a reference point that I find really useful depending on where you are trying to put the focus of your information.
Let’s say I have this data:
Average client satisfaction by Race
White: 86%
Black: 45%
Hispanic: 56%
Asian: 80%
If I only care about certain categories:
I can talk about those groups in relation to an average instead of a reference category, and that average can still include the other categories.
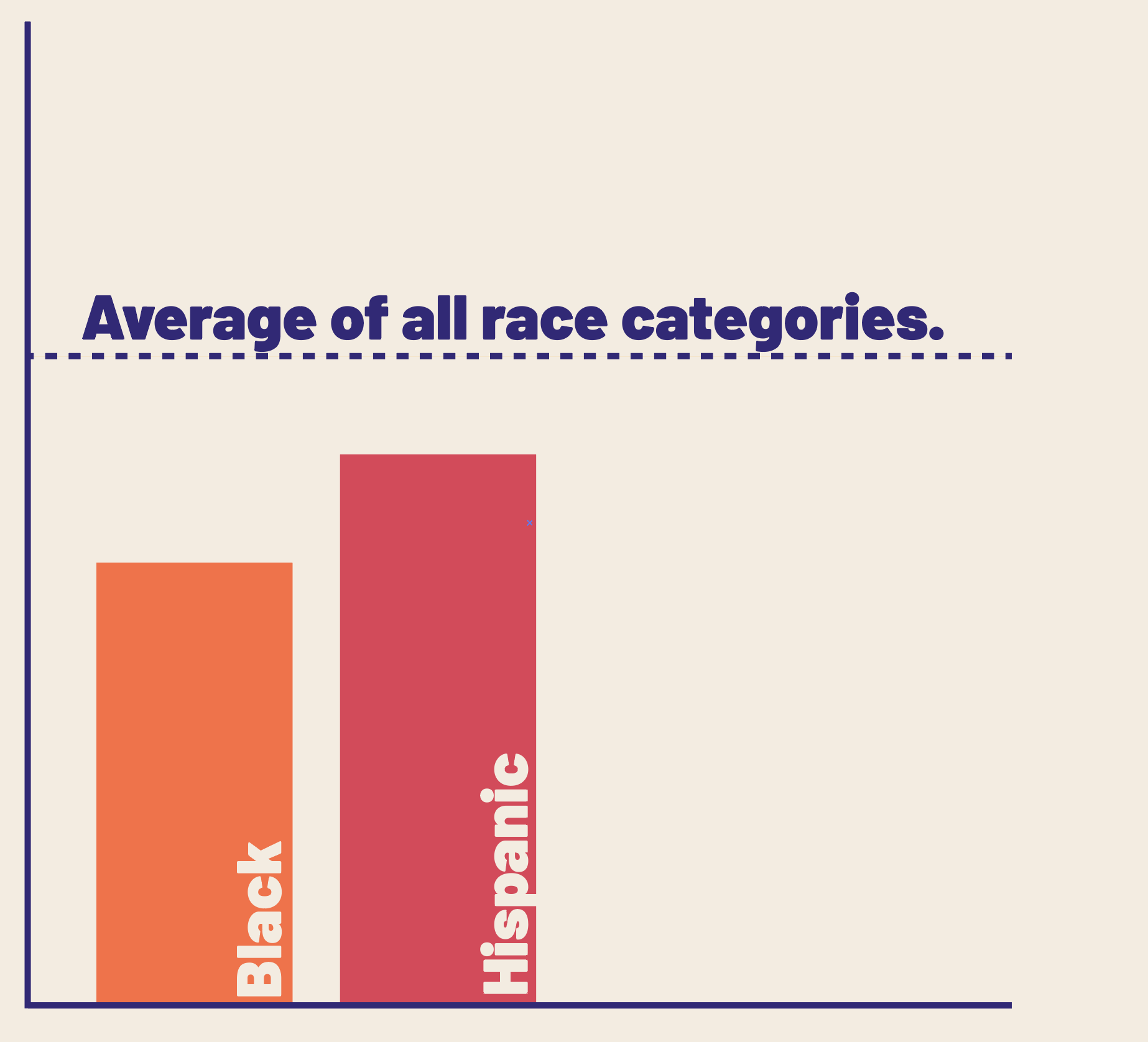
If want to talk about differences above a category:
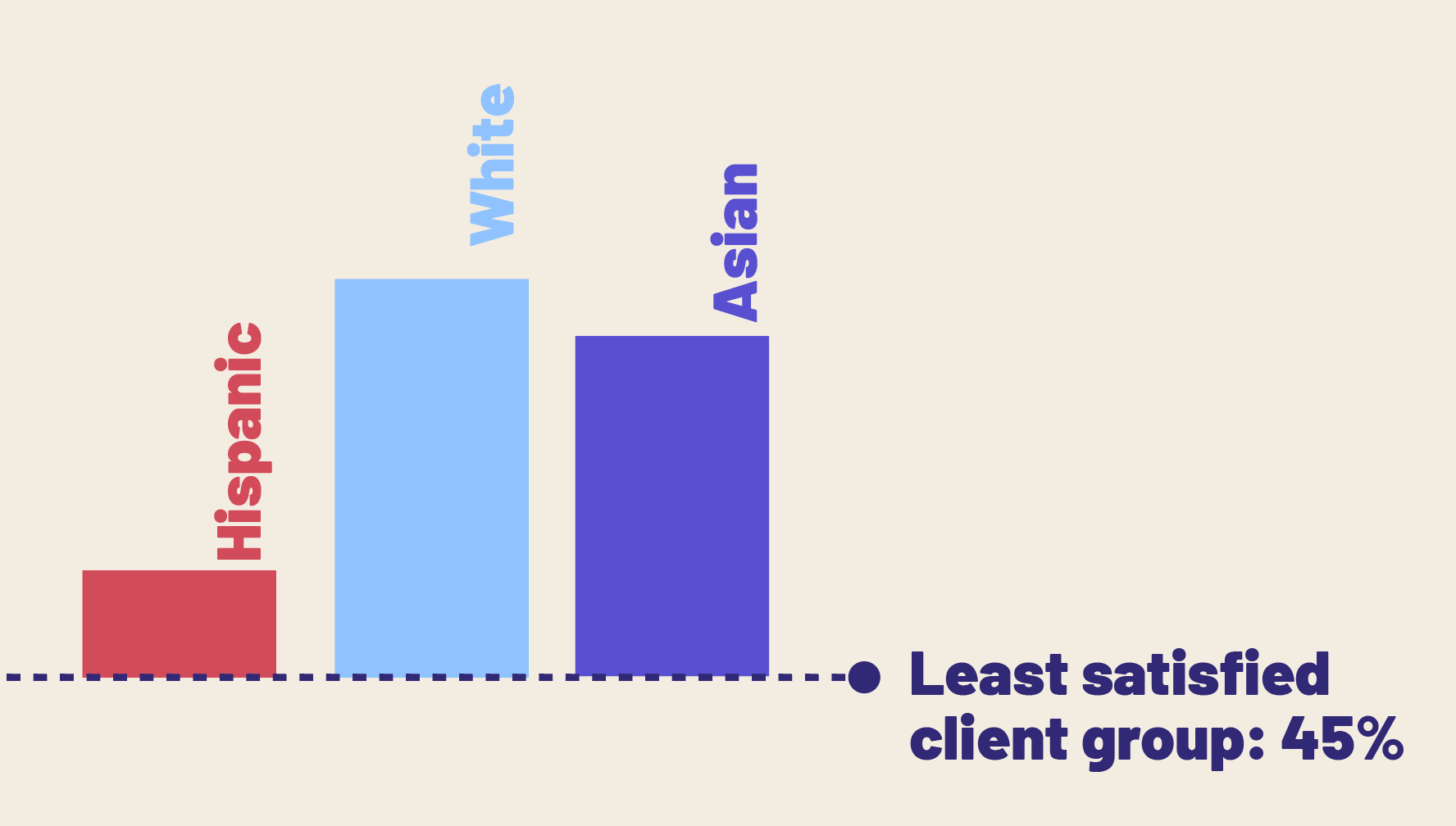
If I want to put focus on the difference between certain categories and the lowest performing category, I can report it that way, regardless of what the lower category is (and in fact, it might change over time across reports/projects). This way you aren’t arbitrarily choosing to always set up a prevailing dichotomy (in this example Black vs White), you are comparing categories against the worst and you don’t have to name it. (This can also work in reverse where you compare specific categories against an unnamed “highest” category).
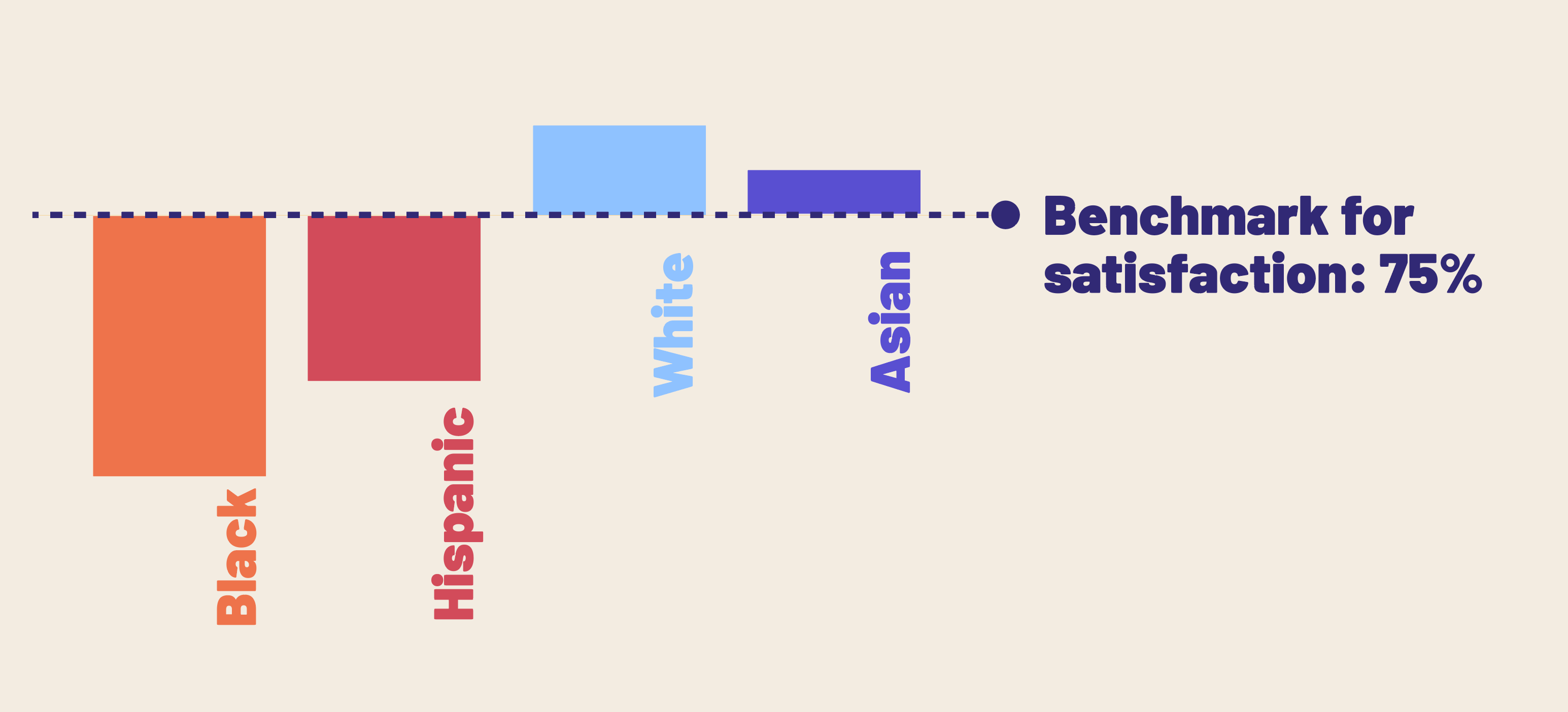
If I want to compare against a meaningful benchmark:
Instead of looking at gap between categories, we can compare under/over performance to a meaningful benchmark to our organization. I really like this one for its subtle yet powerful suggestion that we are measuring ourselves not the characteristics of clients/types of people.
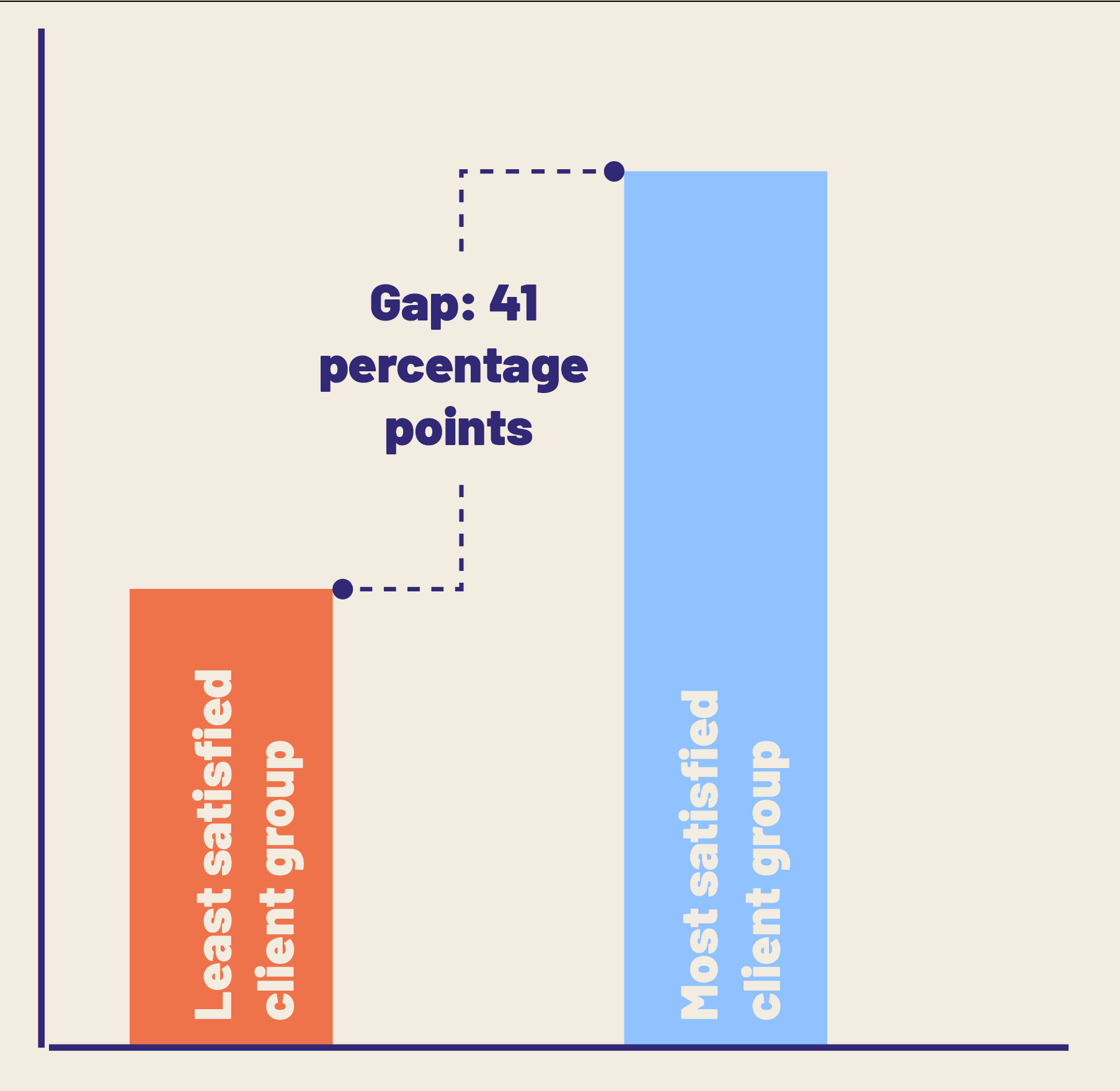
If I care about gaps, but don’t need to emphasize specific pair by pair groups:
We might just care about the existence and magnitude of a gap regardless of who it’s between, especially at the beginning of exploring these issues, or if the consequences of identifying and describing the gap won’t require information about which groups they are between. By burying the group names, we don’t leave any room for prejudice based on prior assumptions about people.
Of course, each of these has pros and cons and ultimately, to choose we need to know what we’re trying to accomplish. When you say:
I totally get what you mean, but I also think that this whole question points to what I call a “negative rationale” in that you might not have a specific group or perspective you know you want to prioritize, but you do have some stuff you don’t want to do:
It can be useful to engage with this question: “What do I want to have happen when I release this research on differences?” How do you want that information to be used and how do you want people to feel about it?
This is so, so helpful — thank you! I’m presenting this back to my team and I know it’ll give us a better path forward. I love your suggestion re: thinking about how we want the information to be applied/understood by the end reader. We may well utilize multiple of these approaches for different research questions instead of trying to find one solution that may not always apply. I appreciate you both engaging with my question and this community very much!
This all makes sense! Thank you @devyani for the question and @bvancil and @Heather for the replies!
When I first saw @devyani 's question, my initial answer would have been ‘Wouldn’t it depend on the research question’?
If my RQ does have something to do with comparing responses for groups, the question would guide which is the reference group (e.g., differences in experiences; does X group report a worse experience than Y group, Y is the reference).
If I don’t have that RQ, or as you say, there’s no specific community focus for the research, and my RQ is more about ‘controlling for’ Race in the model (to the extent that it statistically can be, and understanding what Race actually means in your model), then I would de-prioritize sharing the resulting coefficients as it was not the focus of your analysis and interpretation based on the reference group could be misleading.
My next thought would be, for looking at trends in experiences, is it possible to look within groups? Rather than trying to model all racial groups at once with Race as a variable, disaggregate and look at just one group at a time? I know it decreases sample size, but a good graph is worth ten thousand words. Then, changes over time in perceptions of the support focuses on the experiences of that one group, rather than focusing on their experiences relative to another group.
Just my two thoughts. Thank you all for the discussion!
Great insights @JNeisler I really like the suggestion that looking at one social group at a time in order to gain understanding might be the best option for some RQs. As well, within group analysis can often provide the most useful and effective insights. With emerging methods, small sample sizes are not always the giant issue that they are claimed to be ![]()